Fast and online palindrome counting
For a recent project, I had to deal with the following subproblem.
Problem
Given an alphabet \(\Sigma\) and some property \(P\) (not relevant to this post), find the length of the largest string that exhibits \(P\) and also has the maximum number of distinct palindromes possible for a string of that size. It is known that there is a finite number of such strings.
Naturally, this calls for a simple backtracking solution where we start with the first letter in the alphabet and generate strings in lexicographic order. With each new string generated, if it satisfies \(P\) and has the maximum number of possible palindromes then we follow that search path in the tree; otherwise, we prune it. However, the strings we are dealing with could go up to millions of characters. So we need to do this as fast as possible. But first, let’s have some background.
Preliminaries
The first thing to observe is that a string of length \(n\) will have at most \(n\) palindromes (excluding the empty string). To convince yourself, try to construct a string by adding one letter at a time, and each time look at how many new distinct palindromes this new letter creates (it will be at most one).
Hence, in our backtracking algorithm, we want to maintain the number of palindromes that the current string has. With each letter added or removed, the algorithm should very quickly find the new number of palindromes. If a letter is added to the end then the number may increase, and if a letter is deleted from the end then it may decrease.
Such an algorithm is given by Rubinchik and Shur (paper link), where the primary idea is to construct a graph where each node represents a unique palindrome. This approach was first proposed by Mikhail Rubinchik at the Петрозаводск (Petrozavodsk) summer camp 2014.
The data structure
There are two types of edges (pointers) in the data structure.
- Border edge: A directed edge from \(p\) to \(q\) labeled \(a\), if \(q = apa\) for some \(a \in \Sigma\).
- Suffix edge: An unlabeled directed edge from \(p\) to \(q\), if \(q\) is the longest proper palindromic suffix of \(p\).
Note that there could be a border edge for each possible letter, but there will be exactly one suffix edge for each palindrome.
Whenever we append a new letter to an already processed string, it takes amortized constant time to maintain this graph. Below is an example graph for the string aababba.
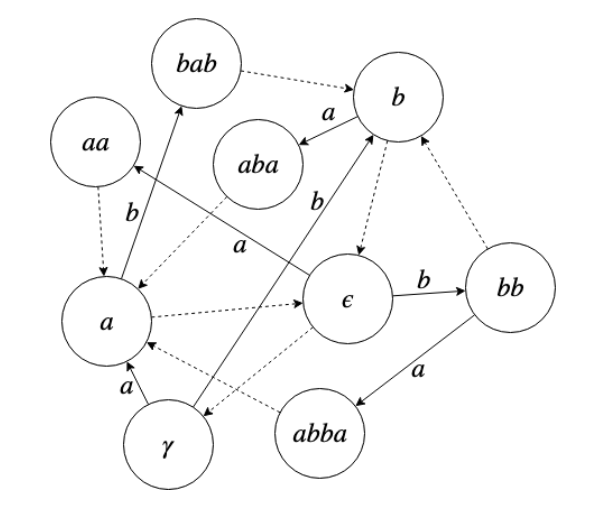
Here \(\epsilon\) denotes the empty string and \(\gamma\) is an imaginary palindrome of length \(-1\). The suffix edges are shown by dashed lines, while the border edges are shown by solid lines with labels. We say that a palindrome consisting of a single letter borders \(\gamma\), which makes the implementation of the algorithm easy.
The algorithm
First, note that this graph will be a tree of nodes where each node will represent a palindrome. So we define a struct Palindrome with the following properties and create a tree of them.
1
2
3
4
5
6
7
8
9
struct Palindrome
{
int envelope[ALPH];
int renvelope[ALPH];
int len;
int lspIndex;
};
vector<Palindrome> Tree;
Here, ALPH is the size of the alphabet \(\Sigma\), required to enable adding edges for each possible letter. The value of Tree[u].envelope[i] stores the index v such that Tree[v] represents the palindrome i Tree[u] i; The array Tree[u].renvelope is just the reverse map for envelope. Note that i represents a single letter here and Tree[u] represents the palindrome at index u. Thus, envelope maintains the border edges defined above.
We do not store the complete palindrome, but only a representation, which saves a lot of space. The field len stores the length of the palindrome, and lspIndex stores the index of the longest proper palindromic suffix of this palindrome. Thus, lspIndex provides the suffix edge defined above.
Now the algorithm is straightforward.
- When a new letter
nextCharis added to the stringSat the last positionpos, start from the current longest palindromic suffix (call itLSP) in the string. - Go through suffix links to find the
candidatesuffix that may produce a new palindrome. It is guaranteed that we will find a candidate because we have the imaginary palindrome \(\gamma\) of length \(-1\). This is done as follows1 2 3 4 5 6 7 8 9 10 11 12 13
candidate = LSP; while (true) { int length = Tree[candidate].len; if (S[pos - length - 1] == nextChar) { // Found the right candidate. break; } // If this was not the right candidate, follow its suffix edge. candidate = Tree[candidate].lspIndex; }
- After this loop, if the corresponding envelope is empty, we know that
nextChargenerates a new palindrome; otherwise it already exists.1 2 3 4 5 6 7 8 9 10 11
candidate = LSP; if (Tree[candidate].envelope[nextChar] == 0) { // We have a new palindrome "nextChar Tree[candidate] nextChar". LSP++; Tree[LSP].len = Tree[candidate].len + 2; // Set the envelope to go from candidate to this new palindrome. Tree[candidate].envelope[nextChar] = LSP; Tree[LSP].renvelope[nextChar] = candidate; }
- Finally, set
Tree[LSP].lspIndexcorresponding to the suffix edge for the new palindrome. This can be found again by traversing via suffix edges from the final candidate.
Space and time requirements
If the string can be of length up to \(n\), then there are no more than \(n+2\) nodes in the tree. This is because there will be at most \(n+2\) palindromes including \(\epsilon\) and \(\gamma\). Hence, the space complexity is \(O(n)\).
To think about the time complexity, note that following a suffix edge always reduces the length of the current longest palindromic suffix. The length cannot be reduced more than \(n\) times, hence, the amortized cost across all updates is \(O(n)\), which makes the average cost of maintenance per update \(O(1)\).